AI Will Eat Simulation Software (and this may be bad.)

My lab runs on simulation software. COMSOL for finite element modeling. Lumerical and Tidy3D for photonic FDTD. Sonnet and sometimes Palace for microwave circuits. We design quantum devices — mechanical resonators, superconducting circuits, photonic waveguides — and before anything gets fabricated, it gets simulated. "An hour of COMSOL can save a month of fab and measurement". Some students joke that we are in fact the COMSOL-verification lab at Stanford. These tools are an essential part of an Applied Physicist/Engineer's toolkit. And I'm starting to worry that they're totally doomed.
Not because they're bad. Because AI makes them too easy to replicate.
The problem
Simulation software has a property that most software doesn't: its outputs are completely verifiable. If I write an EM solver and simulate a electromagnetic structure with a known analytical solution, I can check the answer. If the numbers match, the code works. No subjective judgment, no expert review needed... just physics.
That matters, because it means an AI coding agent can write simulation code, run it against benchmarks, see that it's wrong, fix it, and iterate. The verification loop that's hard for a lot of AI-generated work is trivial here.
And the knowledge-base is wide open. You can't copyright Maxwell's equations. FDTD is in textbooks and open-source codes. Same with Finite element and other methods that are taught in many engineering and physics graduate programs and used by commercial tools. The algorithms are published, the physics is free, and the academic literature describes everything in exquisite detail. That's the whole point of science and academic literature in the field.
So here's what happens: someone with access to any solver, or even a large collection of analytically solvable examples, generates a set of examples, hands those results plus the published algorithm to a coding agent, and says "reproduce this." The verification set is the key. Once you have ground truth, building the solver is just... implementation. And implementation is exactly what these AI agents are good at.
Commercial simulation companies sell validated implementations, optimized performance, support infrastructure, and accumulated engineering. But AI can run its own convergence studies. LLMs can read optimization papers and apply them. Talking to Claude about the problem you're having right now is faster than scouring forums and waiting for replies. And accumulated engineering is a time advantage. It's a fine moat when replication takes years, but not when it takes days.
Why this is probably worse than the problem in journalism
This reminds me of something that's already happened in journalism. The NYTimes Wirecutter, for example, built a business on expert product reviews. People visited the site, saw ads, the ads paid reviewers. Now you can ask an LLM to read every product review online and synthesize a recommendation. Nobody visits. Ad revenue collapses. Reviewers get laid off. Eventually the AI has nothing good left to aggregate — because nobody's paying to produce the reviews anymore. The ecosystem eats itself. Similar worries exist with Stack Overflow and many other website-based businesses.
Simulation software faces the same dynamic, but it's harder to fix. With media, there are levers: copyright law, paywalls, licensing deals with AI companies. Some publishers are pulling those levers now.
With simulation software? The underlying knowledge is physics. Published in peer-reviewed journals specifically so that it can be freely used. You can't put Maxwell's equations or the equations of elasticity behind a paywall. You can't copyright the finite element method. Computational science is built on open knowledge. That openness is now is a vulnerability for companies that sell simulation software.
So who funds the development of new numerical methods when the implementation has zero moat? The incentive to publish might survive — reputation matters in academia. But the incentive to commercialize collapses. And without commercialization, we lose the production-grade, established, tested and verified tools that have made so much of modern engineering possible. Before gaming some scenarios below in "So what happens", I want to go into my experience which got me a bit worried in the first place.
What happened when I tried it
Let me make this concrete with something that happened in my own lab.
amirwg: the mode solver (sorry about the name)
A couple of years ago, I decided to write my own optical waveguide mode solver using the finite element method. I wanted to understand how FEM works. This was for my personal enjoyment and also to see if it's something I can include in a course some day.
I spent a lot of time on it. I got a semi-vectorial finite element solver working — it could mesh a waveguide cross-section into triangles, assemble stiffness and mass matrices, solve the eigenvalue problem to find guided modes. Basic stuff. The code was messy. The full-vectorial solver never gave correct eigenvalues, I probably had a mistake somewhere. Extending it to new geometries was painful. The point of that exercise wasn't really to have a working code — it was for me to learn.
Then, a couple of months ago, I handed that broken codebase to Claude. Claude leveraged open source packages like gmsh and scikit-fem.
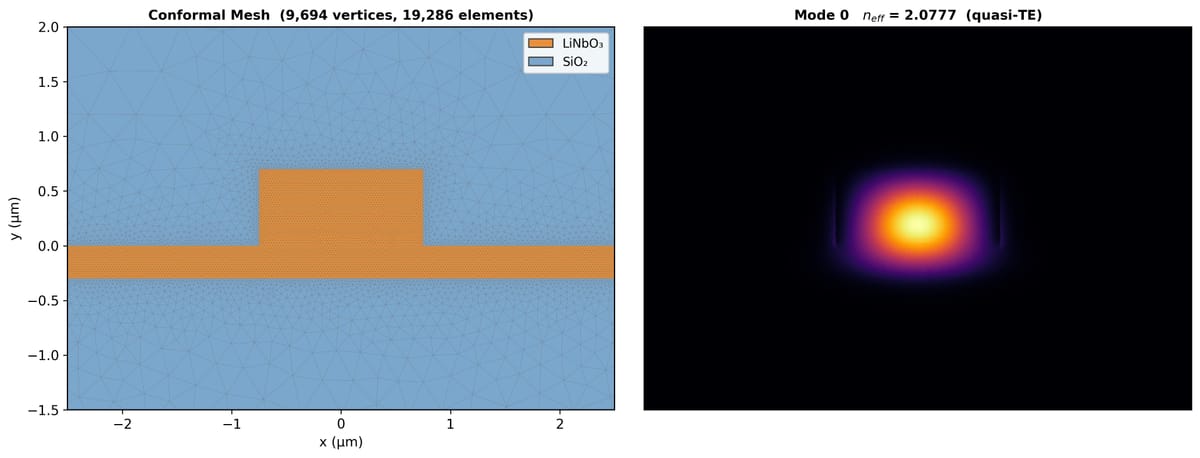
What came back was something I couldn't have built without a time investment that would seriously cut into my day job. A modular mode solver framework with:
- A proper material system with Sellmeier dispersion
- A geometry engine supporting ridge waveguides, dual ridges, and channels, with conformal triangle meshing
- Wavelength sweeps, convergence studies, parameter scans
- Publication-quality plots — mode profiles, effective index spectra, mesh visualizations

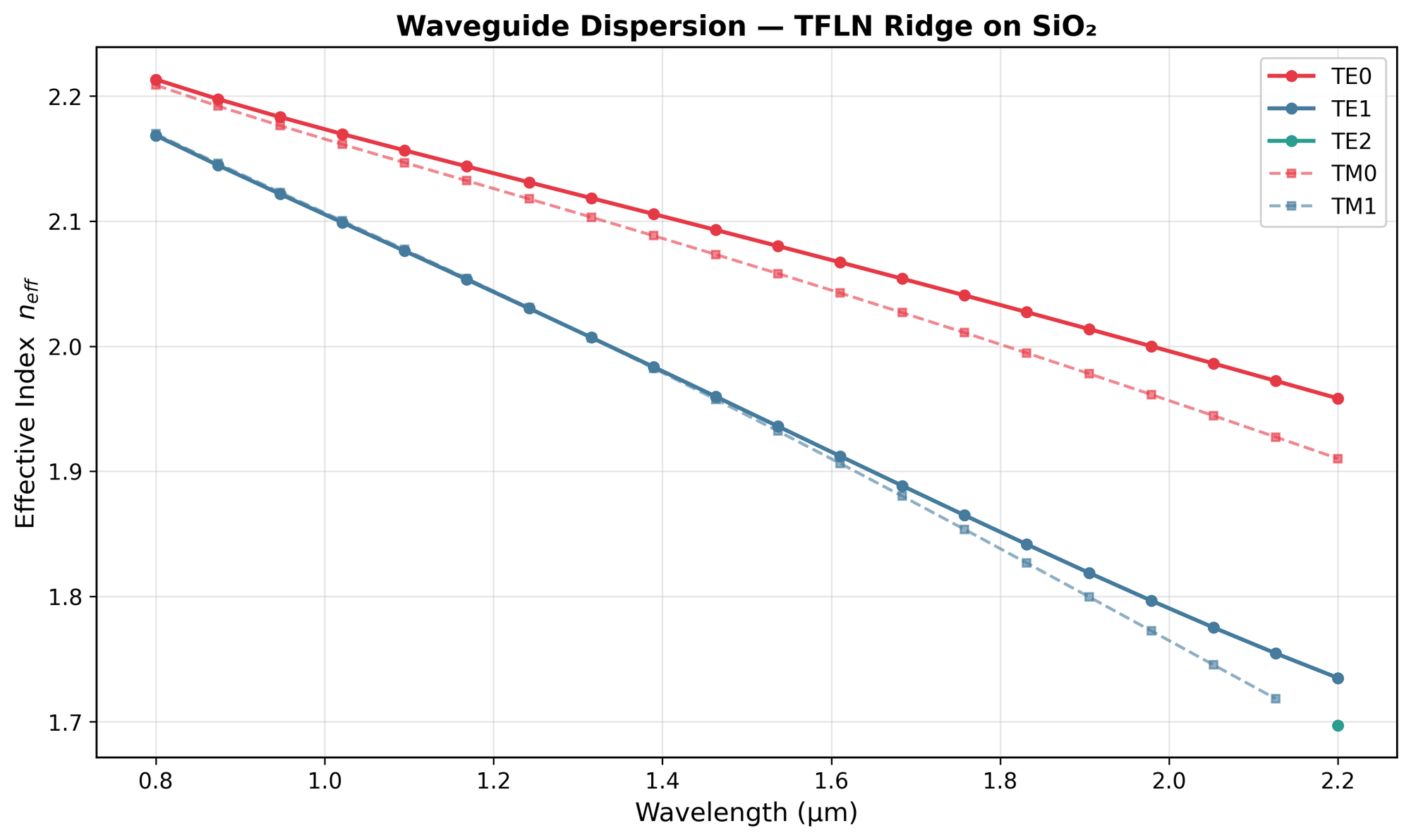
The semi-vectorial solver that had taken me a couple of months of frustrated evenings was cleaned up and made robust in a single session. And, this is the key, I could verify the result against analytical solutions and WGMODES, an open-source MATLAB mode solver by Thomas Murphy at UMD. The verification was easy, Claude even set up the comparison tests. The implementation was the hard part, and Claude also made that trivial.
So what happens?
I see a few scenarios. None of them are great for the incumbents, some are good for accelerating science. One of them is bad for everyone.
The open-source path. Simulation software becomes like Linux or OpenSSL — critical infrastructure maintained by a small community on grants and goodwill. Meep is already this. But Meep took years to build, a dedicated team to maintain, and it still doesn't compete with Lumerical or Tidy3D on features or usability. Will leveraging AI tools allow the same small open source team to build a trust-worthy MEEP that is fast (e.g. GPU accelerated), more user friendly, and with more advanced features?
Verification as the product. If anyone can build a solver, the scarce resource isn't computation, it's trust. Did the AI-generated code handle the corner cases? How well can I trust the dispersion diagrams it's generating (enough for a tape-out that could cost many hundred thousand dollars?) Maybe the valuable service becomes pollable verifiers: authoritative systems that can certify a simulation result is correct. You don't pay for the solver — you pay for the stamp that says the answer is trustworthy enough for your chip tapeout or for your satellite design review. The simulation companies that survive might look less like software vendors and more like Underwriters Laboratories: selling validation, not computation.
The data moat. The physics is open, but engineering data isn't. Foundry-specific process design kits, validated material databases, experimentally calibrated models — these are proprietary and hard to replicate from papers alone. A company that owns the trusted data layer might survive even if the solver layer gets commoditized. This is basically what happened in EDA: the synthesis algorithms are well-known, but the cell libraries and PDKs are where the lock-in lives. To be fair, I'm not sure how much of a moat this is... and besides, it may benefit foundries for everyone to have access to the best data and experimentally calibrated models.
The fragmentation dystopia. This is the one that worries me most. The incumbents go out of business, the the market for trust isn't robust enough to support a large coherent effort with good institutional memory. And so the simulation world fractures into a million AI-generated GitHub repos, each built for a specific problem, none maintained, none systematically validated. Engineers spend more time debugging bespoke solvers than doing engineering. Subtle numerical bugs go unnoticed because no one runs the full validation suites that commercial vendors do. We trade expensive-but-reliable for free-but-fragile. This makes engineering worse, and impedes scientific progress. We should think about this before we lose the institutional knowledge that was embedded in those commercial tools.
I don't know which of these wins. Probably some messy combination. But I do think anyone building or investing in simulation software needs to be thinking about this now. My experience with electromagnetics simulators leads me to think that the window is closing faster than most people realize.
Well, I know, because for a specific problem in electromagnetic design, I closed it myself. On a MacBook. In a few days.
I used LLMs to help me write/proofread this.



![Fidelity, Fisher Information, QCRB and All that [pt. 1]](/content/images/size/w600/2025/05/IMG_3285.jpeg)